2026 年,大模型在编程领域的应用愈发深入,但针对 Android / 移动端开发的专属能力评测始终缺乏统一标准。近日谷歌正式发布Android Bench基准测试框架,专门衡量大语言模型在 Android 开发场景的实战能力。测试结果显示,谷歌自家的Gemini 3.1 Pro Preview以 72.4% 的得分遥遥领先,Anthropic 的 Claude Opus 4.6(66.6%)、OpenAI 的 GPT-5.2-Codex(62.5%)分列二三位。
这份榜单是否能作为 Android 开发者选择 AI 工具的核心参考?其背后的评测逻辑、公正性保障与局限性,值得深入拆解。
Android Bench:专为 Android 开发定制的评测框架
Android Bench 的设计灵感源自经典的 SWE-bench 编程评测基准,但针对 Android / 移动端开发场景进行了深度定制,填补了该领域通用技能测试的空白(区别于小红书 SWE-Bench Mobile 更偏向真实业务场景的定位)。
其核心评测逻辑是**“不看代码形式,只看功能结果”**:让模型生成代码补丁(Patch),应用到真实 Android 项目中,通过项目自带的自动化测试套件验证是否能修复 Bug、通过所有单元测试 / 集成测试,以此判断模型的开发能力。
两阶段分离架构:确保评测客观性
Android Bench 采用 “推理 - 评估” 两阶段分离设计,从流程上规避主观偏差:
-
推理阶段(Agent):加载任务描述、读取问题与代码库、构建提示词、调用 LLM 生成补丁并保存;
-
评估阶段(Verifier):加载模型生成的补丁,在 Docker 沙箱中应用、编译项目、运行测试套件、对比预期结果打分,最终输出评估报告。
七大核心机制:保障评测公正性
为避免环境差异、模型作弊、测试不稳定等因素影响结果,Android Bench 设计了七重保障机制:
| 保障层次 | 核心机制 | 作用效果 |
|---|---|---|
| 环境隔离 | Docker + KVM 沙箱虚拟化 | 每个任务运行在独立容器,支持 Android 模拟器,消除主机环境差异,所有模型共享相同运行环境 |
| 代码隔离 | git apply --exclude过滤测试文件 |
防止模型篡改测试用例 “作弊”,测试文件由框架单独注入,仅验证业务代码修复效果 |
| 版本锁定 | 固定 Git Commit 哈希值 | 所有模型面对完全相同的代码快照,避免因代码版本差异导致的评测偏差 |
| 双维度验证 | fail_to_pass(修复后应通过的测试)+ pass_to_pass(修复后仍需通过的测试) |
既要求模型修复目标 Bug,又要避免引入新的回归问题,符合真实开发要求 |
| 抗不稳定测试 | 多次重试 + 去抖机制 | 应对偶发的 Flaky 测试,失败后自动重试,区分 “稳定通过” 与 “波动通过”,减少结果噪声 |
| 自验证机制 | Oracle Agent + Golden Patch(标准答案补丁) | 验证评测基础设施的正确性,若标准答案无法通过测试,则判定任务配置无效 |
| 防数据泄漏 | Canary GUID 标记 | 检测模型训练数据是否包含评测数据集,避免 “应试式” 优化影响评测真实性 |
测试数据集:覆盖 Android 核心开发场景
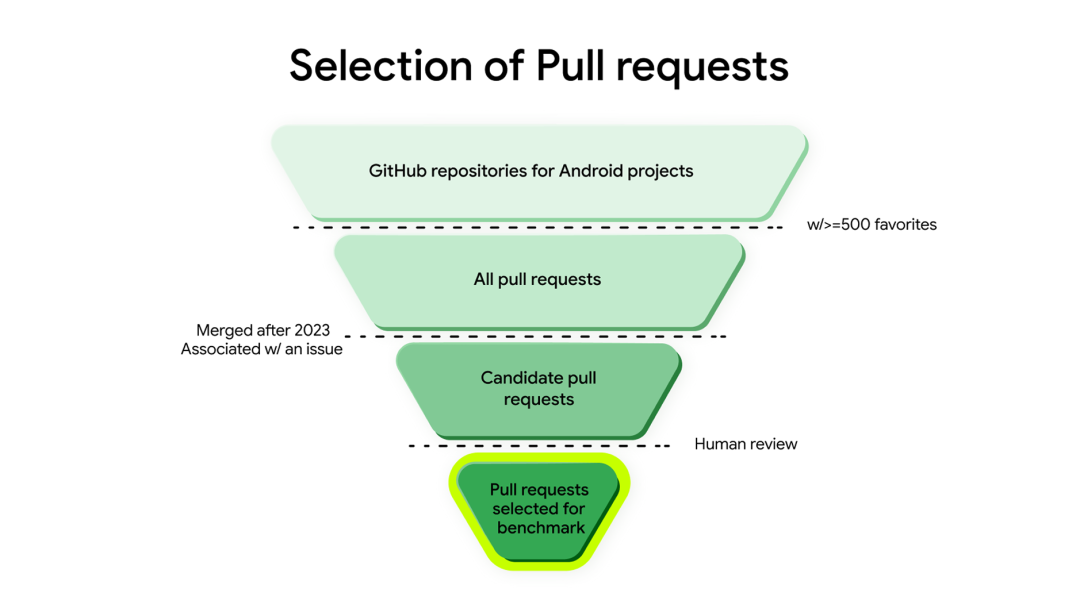
Android Bench 的测试任务并非随机选取,而是从 38,989 个 GitHub Pull Request 中,经机器筛选 + 两轮人工审核,最终确定 100 个核心任务,覆盖 Android 开发的主流场景与技术热点:
-
核心框架:Jetpack Compose、Coroutines/Flow、Room、Hilt、Navigation 迁移;
-
工程配置:Gradle 构建优化、SDK 版本适配、Breaking Changes 处理;
-
系统能力:System UI、Camera、Media 等系统 API 调用;
-
特殊场景:配置变化适配、折叠屏适配、运行时权限管理等。
评测核心聚焦 “Android 工程上下文理解 + 中小规模补丁生成 + 构建与测试通过” 的综合能力,更贴近日常开发中的 Bug 修复与小功能开发场景。
实测排名:Gemini 领跑,头部模型差距缩小
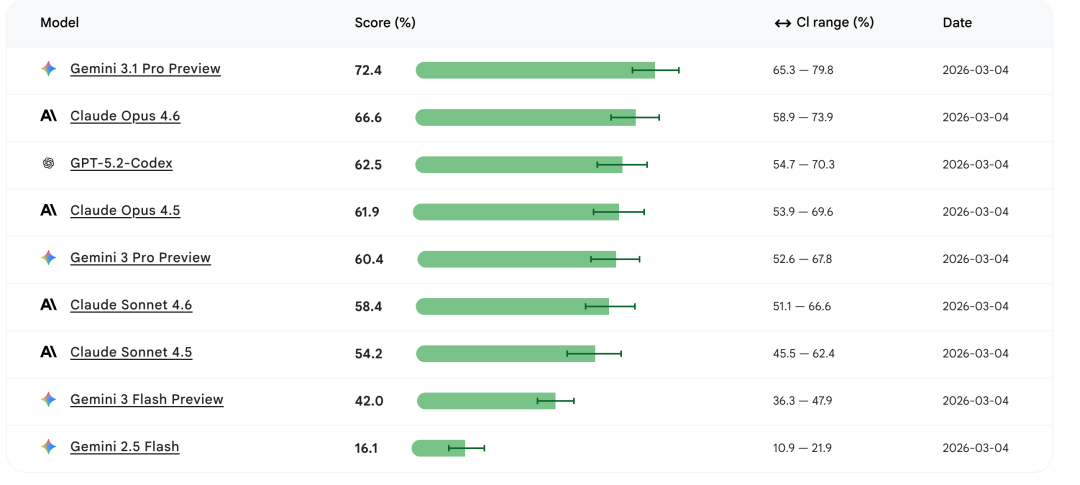
本次测试涵盖 9 款主流大模型,每个模型对 100 个任务重复测试 10 次,最终得分取平均成功率,并标注置信区间(CI),结果如下:
| 模型名称 | 得分(%) | 置信区间(%) |
|---|---|---|
| Gemini 3.1 Pro Preview | 72.4 | 65.3-79.8 |
| Claude Opus 4.6 | 66.6 | 58.9-73.9 |
| GPT-5.2-Codex | 62.5 | 54.7-70.3 |
| Claude Opus 4.5 | 61.9 | 53.9-69.6 |
| Gemini 3 Pro Preview | 60.4 | 52.6-67.8 |
| Claude Sonnet 4.6 | 58.4 | 51.1-66.6 |
| Claude Sonnet 4.5 | 54.2 | 45.5-62.4 |
| Gemini 3 Flash Preview | 42.0 | 36.3-47.9 |
| Gemini 2.5 Flash | 16.1 | 10.9-21.9 |
从结果来看,Gemini 3.1 Pro 凭借对 Android 生态的深度适配,以近 6 个百分点的优势领跑;Claude Opus 系列紧随其后,展现出强劲的跨平台编程能力;GPT-5.2-Codex 作为专门的编码模型,稳居第三梯队;而 Gemini 2.5 Flash 等轻量模型则因能力定位,得分差距较大。
评测局限性:参考价值需理性看待
尽管 Android Bench 的设计已相对完善,但仍存在一些局限性,开发者选择 AI 工具时需结合实际场景判断:
-
任务场景偏向性:测试任务以 “修 Bug、小功能开发” 为主,人工策展的数据集并非纯自然分布,无法完全代表复杂需求开发(如大型功能架构设计、跨模块协作);
-
Agent 外壳压制模型潜力:所有模型均在统一的 mini-SWE-agent 外壳下运行,通过 LiteLLM 作为接口层,可能无法发挥部分模型在自家专属代理系统中的最优表现(如 Claude 在 Claude Code 代理下的能力未被完全释放);
-
与真实业务场景有差距:相比小红书 SWE-Bench Mobile 聚焦真实业务的测试(iOS 场景通过率仅 12%),Android Bench 的通用场景测试结果更偏向 “理想环境”,实际开发中需应对更复杂的业务逻辑与工程约束。
开发者选型建议:按需选择,避免盲目跟风
结合 Android Bench 的评测结果与局限性,给 Android 开发者的 AI 工具选型建议如下:
-
若以 Jetpack Compose、系统 API 适配等 Android 原生场景开发为主,Gemini 3.1 Pro是首选,其对 Android 生态的理解与兼容性更具优势;
-
若涉及跨平台开发、复杂逻辑编码,Claude Opus 4.6值得尝试,其综合编程能力与稳定性在测试中表现突出;
-
若追求性价比,Claude Sonnet 4.6(58.4%)与 GPT-5.2-Codex(62.5%)能满足大部分中小规模开发需求,成本更低;
-
轻量模型(如 Gemini 3 Flash)适合简单语法查询、代码片段生成,不建议用于核心功能开发或 Bug 修复。
此外,实际使用中还需关注模型的响应速度、代码可读性、是否支持自定义提示词等因素,结合自身开发场景进行实测验证,而非单纯依赖榜单排名。
结语:Android 开发 AI 评测迈入标准化时代
谷歌 Android Bench 的发布,填补了 Android 领域大模型编程能力评测的空白,为开发者提供了统一、可参考的标准。尽管存在一定局限性,但它通过严谨的评测机制,客观反映了主流大模型在 Android 开发场景的真实实力,也为模型厂商优化方向提供了明确指引。
随着 AI 与编程的深度融合,未来的评测框架可能会更贴近真实业务场景,纳入更复杂的工程化需求(如性能优化、兼容性适配)。而对开发者而言,AI 终究是提升效率的工具,理性看待评测结果、按需选择,才能让技术真正服务于开发工作。