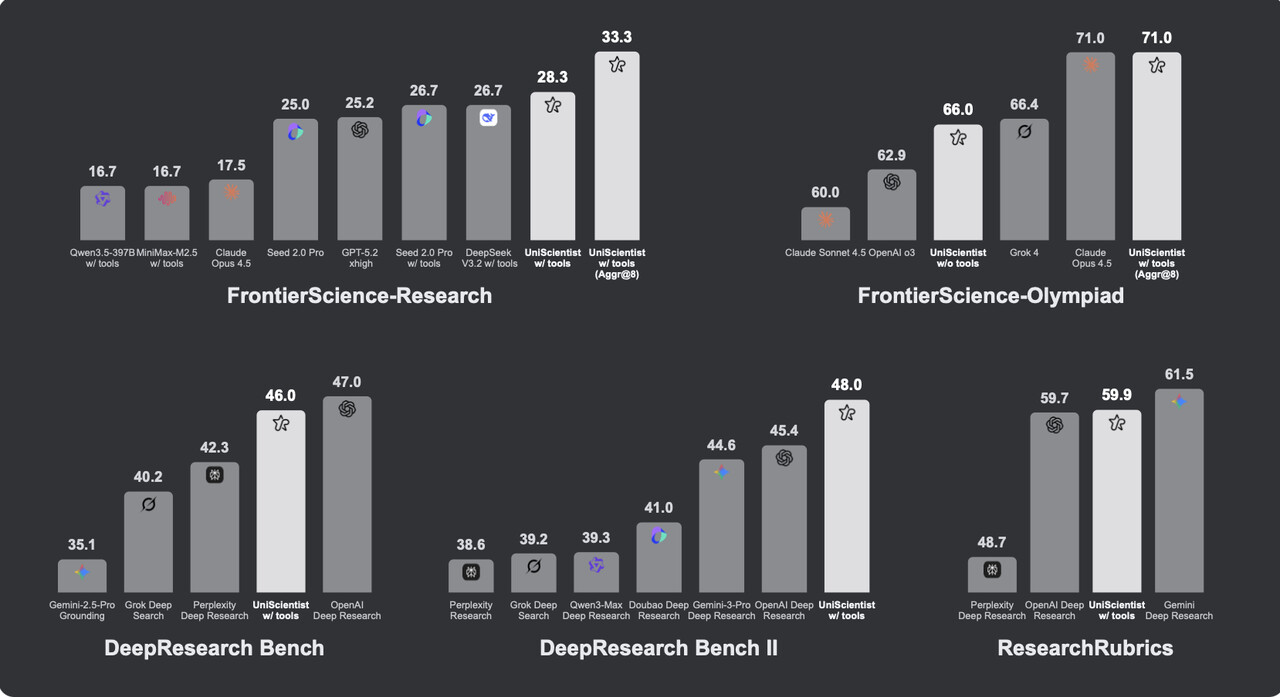
当大家还在比拼模型参数规模时,UniPat AI 用一场 “数据逆袭” 颠覆了行业认知:基于 Qwen3-30B-A3B 基座模型(仅 3B 激活参数),通过自研的高质量科研数据集训练,其开源科研 Agent 模型 UniScientist 在 FrontierScience-Research 榜单上斩获 33.3 分(聚合后),略微超越 GPT-5.4 的 33.0 分,在特定科研能力上实现了 “小模型打败大模型” 的奇迹。
这场胜利的核心并非模型架构的颠覆,而是 UniPat AI 找到了解决科研 AI 痛点的关键 ——高质量、结构化的科研数据。比起模型本身,这套数据的构建逻辑,更能揭示 AI 科研能力突破的底层密码。
一、核心战绩:3B 激活参数,专项能力比肩顶流闭源模型
UniScientist 的成绩单足够亮眼,但需明确其能力边界:它并非通用智能超越,而是在 “开放式科研任务” 这一专项上实现突破 —— 给定科学问题,自主完成文献检索、假设提出、推导仿真、迭代验证、报告撰写的全流程。
关键榜单成绩(聚合后)
| 评测基准 | UniScientist 得分 | 对比模型 | 对比模型得分 |
|---|---|---|---|
| FrontierScience-Research | 33.3 | GPT-5.4 | 33.0 |
| FrontierScience-Olympiad | 71.0 | Claude Opus 4.5 | 71.0 |
| DeepResearch Bench | 46.0 | OpenAI Deep Research | 47.0 |
| DeepResearch Bench II | 48.0 | OpenAI Deep Research | 45.4 |
| ResearchRubrics | 59.9 | OpenAI Deep Research | 59.7 |
值得注意的是,即使不带工具裸跑,UniScientist 的成绩也远超原始基座模型:同一 Qwen3-30B-A3B 模型,未训练时仅得 3 分,用 2000 条科研数据训练后升至 15 分,扩至 4700 条数据后达 28.3 分,25 分的提升纯粹由数据驱动。
二、数据魔法:4700 条科研题,50 + 学科全覆盖
好模型 = 好数据 + 好架构 + 足够算力,这一公式早已被行业认可,但多数模型团队对数据构建避而不谈。UniScientist 的成功,恰恰源于其在数据上的极致投入。

1. 数据集核心规格
-
规模:4700 + 条研究级实例,覆盖物理、数学、生物、化学、计算机等 50 + 学科,400 + 研究方向;
-
结构化设计:每道题配套 20 + 条评分标准(Rubric),每条仅验证一个知识点,将开放科研问题拆解为可量化的 “单元测试”;
-
标注成本:专家平均每条样本投入 1-2 小时,确保数据质量的精准性。
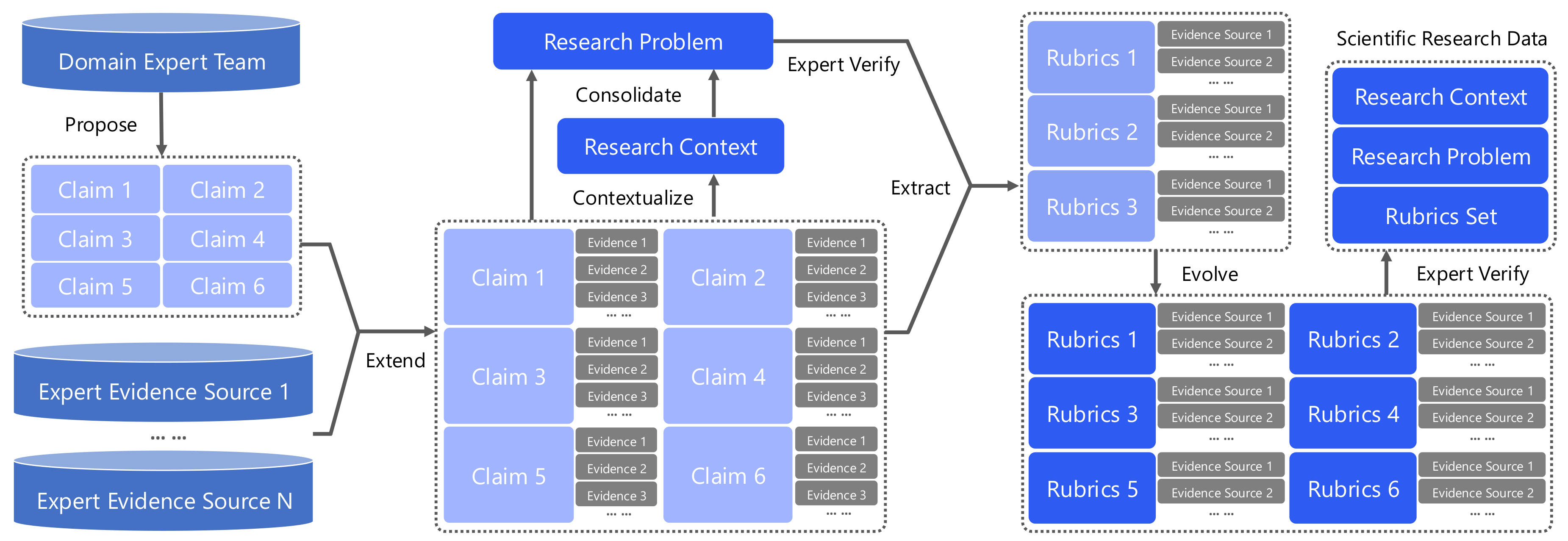
2. 数据构建:踩过两条弯路后,找到 “人机协作” 最优解
UniPat AI 团队在数据构建上并非一帆风顺,曾走过两条低效弯路:
-
纯模型生成:速度快、成本低,但产出内容 “不像人话”,科研术语使用生硬,懂行的硕博一眼就能识别出 “虚假感”;
-
纯人工标注:质量有保障,但效率极低,一条数据标注需数天,且跨学科题目易因专家知识边界导致理解矛盾(如化学博士难以精准标注生物化学交叉问题)。
最终,他们采用 “Human in the Loop” 人机协作流程,实现效率与质量的平衡:
-
专家输入:提供科学论断与权威证据来源,把控核心知识准确性;
-
模型扩展:基于专家输入,跨学科生成完整研究问题与解法草案,弥补人工在规模与多样性上的不足;
-
专家验证:对模型生成内容进行质量校验、修正偏差,确保科研逻辑严谨;
-
Rubric 拆解:从问题中提取原子化评分项,明确每个知识点的验证标准;
-
迭代演化:经过多轮人机交互优化,最终形成 “研究背景 + 研究问题 + 评分标准” 的完整训练数据。
3. 数据质量验证:盲评超越纯人工标注
团队曾做过一场 “科研图灵测试”:让美国高校博士盲评三组题目,判断哪组最像真实研究者撰写 —— 结果显示,“人机协作” 组的评价最高,被认为 “完成度够新晋教授申请项目使用”;而纯人工标注组因专家知识边界限制,部分内容 “一知半解、表述模糊”,反而不如人机协作组真实。
这印证了一个关键结论:在足够专业的跨学科领域,“纯人工标注” 未必比 “人机协作” 更靠谱,模型能突破人类的知识局限,生成更全面、严谨的科研场景。
三、科研题长什么样?从化学到生态学的真实案例
UniScientist 的数据集并非简单的 “选择题” 或 “简答题”,而是完整的科研任务,要求模型走完 “查文献 - 建模型 - 计算 - 验证 - 写报告” 的全流程,以下是两个典型样题:
1. 化学方向:线性四烯热解反应的立体化学分析
-
问题:已知 (Z,Z,Z,E)- 癸 - 2,4,6,8 - 四烯热解反应产物比为 3:1,要求枚举所有对称性不同的环化路径,用 FMO 理论追踪立体化学,建立统计与动力学模型预测产物比,设计实验区分模型,做 DFT 验证与灵敏度分析;
-
评分标准:31 条 Rubric,包括 “明确 Woodward-Hoffmann/FMO 理论依据”“追踪终端甲基原子迁移路径”“枚举对称性不同的环化模式” 等,每条对应一个核心知识点。
2. 生态学方向:植物 - 昆虫群落 ODE 模型分析
-
问题:给定植物 P (t)、三种传粉昆虫 (x1-x3)、三种拮抗昆虫 (y1-y3) 的 ODE 模型参数,要求判断是否存在稳定共存平衡点,计算传粉者最低维持阈值,分析植物崩溃的临界条件;
-
评分标准:24 条 Rubric,涵盖 “完整列出 ODE 系统及参数”“明确数值积分规格”“基于雅可比矩阵分析稳定性”“解释 r 和 K 的生态意义” 等关键步骤。
四、推理流程:22 轮工具调用,17000 字报告满分通关
UniScientist 的推理过程完全模拟人类科研逻辑,以 “镍酞菁 meso 位氮原子修饰” 为例,模型展现了惊人的自主科研能力:
-
工具调用:累计 22 轮工具交互,包括 3 次 Google Scholar 检索、9 次网络搜索、10 次网页访问,即使被 ScienceDirect 拦截,也会自动切换其他数据源;
-
流程闭环:从 “理解 meso 位氮原子定义” 出发,逐步检索合成方法、分析电子结构影响、对比传统酞菁局限性,最终形成 17000 字报告;
-
评分结果:10 条 Rubric 全部满分,精准覆盖 “传统合成局限性分析”“硫醇盐介导四聚化机制”“镍络合对环化的促进作用” 等核心考点。
模型推理时可调用四大工具:网络搜索、Google Scholar、网页抓取、代码执行,支持最多 100 轮交互与多次 rollout 聚合,确保结果的稳健性。
五、模型与开源信息:轻量化架构,全量开放
1. 模型基础规格
-
基座:Qwen3-30B-A3B-Thinking,MoE 架构;
-
激活参数:3B(总参数 30B,仅激活 10%);
-
上下文窗口:128k tokens;
-
训练算力:约 1200 小时 H200 GPU 算力。
2. 开源资源(Apache 2.0 许可)
-
详细 Blog:https://unipat.ai/blog/UniScientist(含完整案例与推理轨迹)。
六、行业启示:数据才是科研 AI 的核心护城河
UniScientist 的成功,给 AI 行业带来了重要启发:
-
科研 AI 的突破,未必需要万亿参数规模,聚焦 “高质量数据 + 精准任务建模”,小模型也能实现专项超越;
-
数据构建的 “人机协作” 模式,有效解决了跨学科、大规模、高质量的矛盾,为领域 AI 数据生成提供了可复用范式;
-
能力迁移效应:用科研数据训练的模型,在通用报告生成等任务上也实现分数提升,说明科研所需的 “证据收集 - 假设验证 - 逻辑闭环” 能力具有普适性。
不过也需理性看待其局限性:当前成绩仅聚焦专项科研能力,通用智能仍不及 GPT-5.4 等大模型;且数据边际效应尚未明确,后续增加数据规模能否持续提升性能仍需观察。
但不可否认,UniScientist 用实践证明了 “数据决胜” 的真理 —— 在 AI 架构日趋同质化的今天,高质量、结构化的领域数据,正在成为新的核心竞争力。