继 Seedance 2.0 成为现象级视频生成应用后,字节跳动携手北大、安努智能、Canva 推出的Helios 视频模型家族再次引爆行业。这款仅 14B 参数量的模型,实现了 19.5 FPS 的单卡实时生成速度,兼顾高质量与高帧率,还在发布首日完成昇腾 NPU 的 Day-0 级别支持,兼容 Diffusers、vLLM-Omni 等主流推理框架,一举登顶 Hugging Face Daily Papers,GitHub 发布数日星数便突破 520。
而 Helios 的惊艳表现,并非凭空诞生 —— 其核心技术与北大袁粒课题组的 Open-Sora Plan(OSP)项目高度同源,更是基于该团队开源的 UniWorld-OSP2.0 实现了性能升级。这背后,一套以鲲鹏 + 昇腾为核心的国产化算力生态,正成为视频生成大模型的强大底座,而 UniWorld-OSP2.0 作为业界首个超百亿级开源视频生成大模型,更是凭借「双原生」特性,成为开源视频生成生态的核心风向标,推动 AI 视频生成迈入工业级实时应用阶段。
Helios:14B 的性能奇迹,国产化底座的硬核验证
Helios 家族包含 Helios-Base、Helios-Mid、Helios-Distilled 三个版本,全面覆盖文本生视频(T2V)、图像生视频(I2V)、视频生视频(V2V)及交互式生成任务,实现了「小参数量 + 高速度 + 高质量」的三重突破。
在实测对比中,Helios-Distilled(14B)无论是短视频还是长视频生成,帧率均大幅领先同参数量的 TurboDiffusion、FastVideoWan 等模型,Tolscore 评分也稳居第一梯队;即便与 19B 的 LTX Video 2 相比,其生成质量也毫不逊色,彻底打破了「大参数量才会有高性能」「实时生成只能是小模型」的行业固有认知。
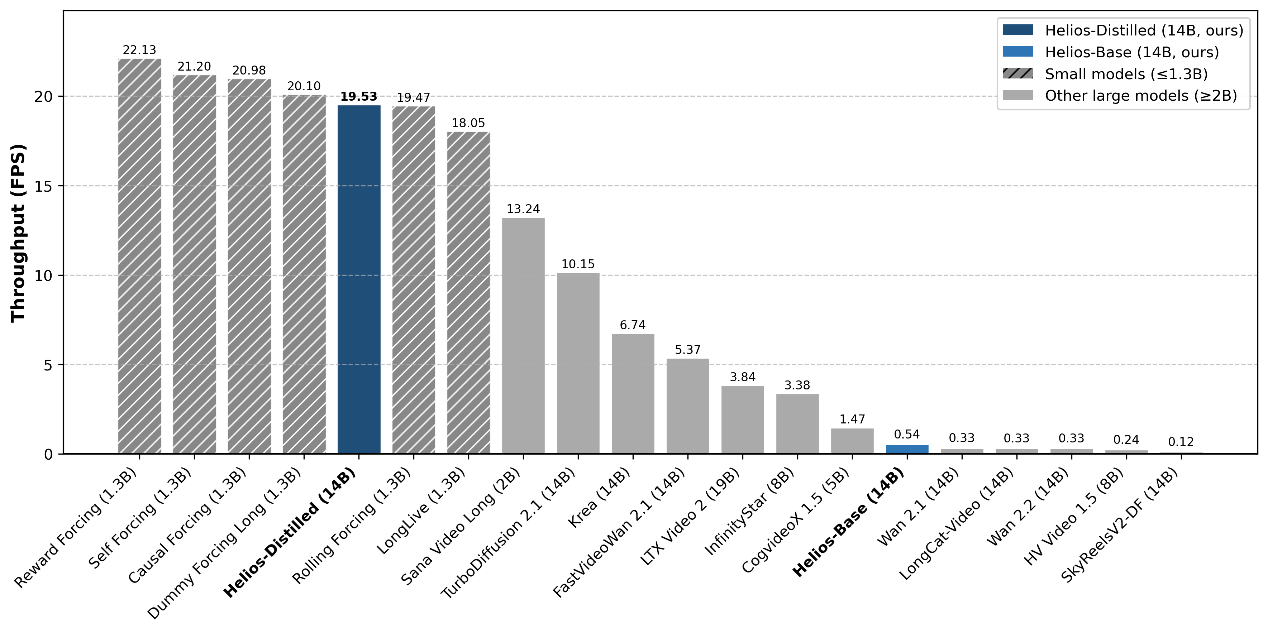
而 Helios 的技术根基,正是北大 OSP 团队开源的 UniWorld-OSP2.0,二者存在三分之一到二分之一的代码复用,Helios 更是在 OSP-RealTime 14B 的基础上实现了性能再升级。可以说,Helios 的成功,本质是对 UniWorld-OSP2.0 核心技术的一次硬核验证,更是对昇腾国产化算力底座适配能力的最佳证明。
UniWorld-OSP2.0:业界首个「双原生」视频大模型,开源生态的核心标杆
作为 Open-Sora Plan 团队的重磅力作,UniWorld-OSP2.0 是业界首个开源的超百亿级视频生成大模型(21B),更是首个实现「双原生」的大模型体系 —— 既做到昇腾原生,深度适配国产化算力;又实现自回归 + Diffusion 混合架构原生,收敛视频生成的统一范式。
目前该模型在 GitHub 已收获 847 星,其依托的 Open-Sora Plan 项目更是累计斩获 1.2 万星、千万级下载量,多次登上 Trending 榜单,字节、腾讯 WXG、阿里达摩院、小红书等国内外企业均基于该框架展开二次开发,让这套高性能、低成本、自主可控的技术框架,逐渐成为视频生成领域的产业级基础设施,推动行业迎来「视觉版 LLaMA 时刻」。
三大核心组件,构筑统一生成架构
UniWorld-OSP2.0 的强大性能,源于其底层设计的三大核心组件的无缝协同,构成了「VAE+VLM+DiT」的经典架构,也为深度适配昇腾算力打下了系统级基础:
-
因果变分自编码器(Causal VAE):作为像素空间与潜在空间的桥梁,将高维视频序列压缩为带因果结构的紧凑表示,在保证时间因果关系的同时,大幅提升处理效率;
-
VLM 增强的多模态条件模块:以冻结的视觉 - 语言模型(VLM)为认知中枢,提取图像 + 文本的多模态深层特征,再通过可训练的 Adapter 模块映射适配,为生成过程提供精准的语义指导;
-
扩散 Transformer(DiT)主干网络:接收语义特征后,在 VAE 潜在空间执行条件去噪,最终合成时间连贯、空间稳定的视频流,是视频生成的核心引擎。
这套架构让模型摆脱了传统视频生成的技术桎梏,在语义理解、物理一致性、生成效率上实现了全方位突破。
FlashI2V:破解物理一致性难题,告别视频僵硬感
长期以来,I2V 生成的最大痛点是条件图像泄漏:传统模型将条件图像直接拼接到去噪器,导致模型过度依赖首帧,生成的视频动作僵硬、色调失调,甚至变成「一张图的循环播放」。
UniWorld-OSP2.0 提出的FlashI2V 核心机制,通过两大设计从根本上解决了这一行业难题,成为视频物理一致性的「定海神针」:
-
潜空间偏移(Latent Shifting):在扩散链路中引入「运动自由度阀门」,通过可学习的投影模块将原始潜变量转换到含高频特征的空间,隐式整合条件图像信息,减少模型对首帧的过度依赖,让视频真正「动起来」,保证动态运动的高保真;
-
傅里叶引导(Fourier Guidance):提取图像傅里叶变换后的高频幅度特征,与噪声潜在空间拼接后输入 DiT,在频域层面校准细节、增强运动预测稳定性,还能通过调整截止频率,细粒度控制视频的细节清晰度,还原文本、纹理等小尺度结构。
实测中,FlashI2V 不仅让生成视频摆脱了像素级的条件图像泄漏,还实现了域内 / 域外数据的稳定泛化,让块式 FVD 指标保持一致,在 VBench-I2V 基准上的主体一致性、背景一致性、运动流畅度等指标全面超越 Wan2.1,稳居开源阵营第一梯队。
两大创新:深化语义理解,解锁可控艺术表达
在解决物理真实感后,UniWorld-OSP2.0 进一步在认知深度与艺术可控性上实现双重突破,让视频生成从「还原现实」走向「理解并创造现实」:
创新一:VLM 加持,重构多模态认知理解
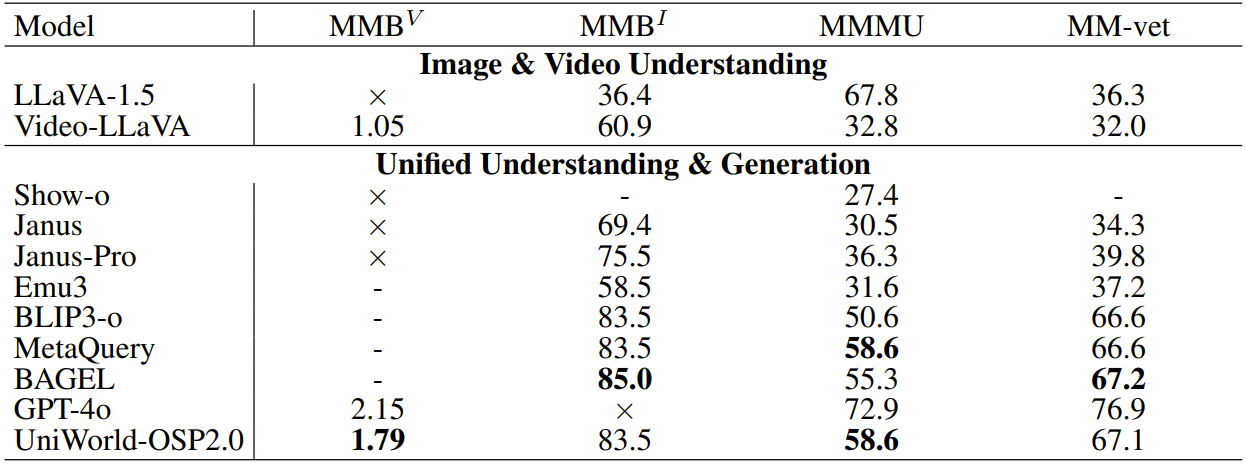
传统视频生成模型依赖纯文本编码器(如 T5),仅能捕获表层词汇线索,难以实现细粒度指令对齐。UniWorld-OSP2.0 引入冻结的预训练 VLM(如 Qwen2.5-VL 7B)作为多模态特征提取器,综合图像与文本提示生成深层跨模态表示,再通过轻量级 Adapter 与 DiT 精准对齐,让模型直接继承 VLM 的视觉基础知识,真正「看懂」复杂场景,大幅提升对角色、动作、场景的细粒度控制精度。在 MMBV、MMB、MMMU 等多模态评测中,该模型表现跻身前列,展现出极强的视觉理解能力。
创新二:I2SV 范式,实现一步式风格化视频生成
以往视频风格化多依赖后期滤镜,风格与内容融合度低,还易出现角色变形、动作漂移。UniWorld-OSP2.0 构建了包含吉卜力、3D 渲染、水墨画、赛博朋克等12 类典型艺术风格的专属数据集,推出全新的I2SV(图像到风格化视频)范式,让模型在生成阶段可同时接收原始图像、文本描述、风格指令,一步输出时间连续、语义一致的风格化视频。配合回环式质量监控策略,有效保留角色动作与语义细节,让艺术表达更可控、更自然。
OSP-RealTime 14B:14B 参数量迈入实时区间,开启工业级应用
过去,视频生成行业的默认逻辑是「大模型 = 高质量 + 低速度,小模型 = 低质量 + 实时」,14B 级别的模型只能做离线生成,而北大团队基于 UniWorld-OSP2.0 训练的OSP-RealTime 14B,彻底打破了这一壁垒 —— 在单块昇腾 Atlas A3 上,文生视频帧率直达 10 FPS,成为首个接近「交互式视频生成」的开源扩散架构,而 Helios 正是在此基础上实现了 19.5 FPS 的进一步突破。
核心设计:把长视频生成变成「无限续写」
OSP-RealTime 14B 将长视频生成重新定义为无限的视频续写任务,摒弃了传统滑动窗口的「拼接式延长」模式(推理与训练范式不一致,质量受限),通过时间维噪声 latent 拼接策略,在时间轴上延续历史噪声状态,让扩散过程在窗口切换时保持运动连续性,在不改变原有训练范式的前提下,实现视频的时间无限延展,保证了生成质量的下限。
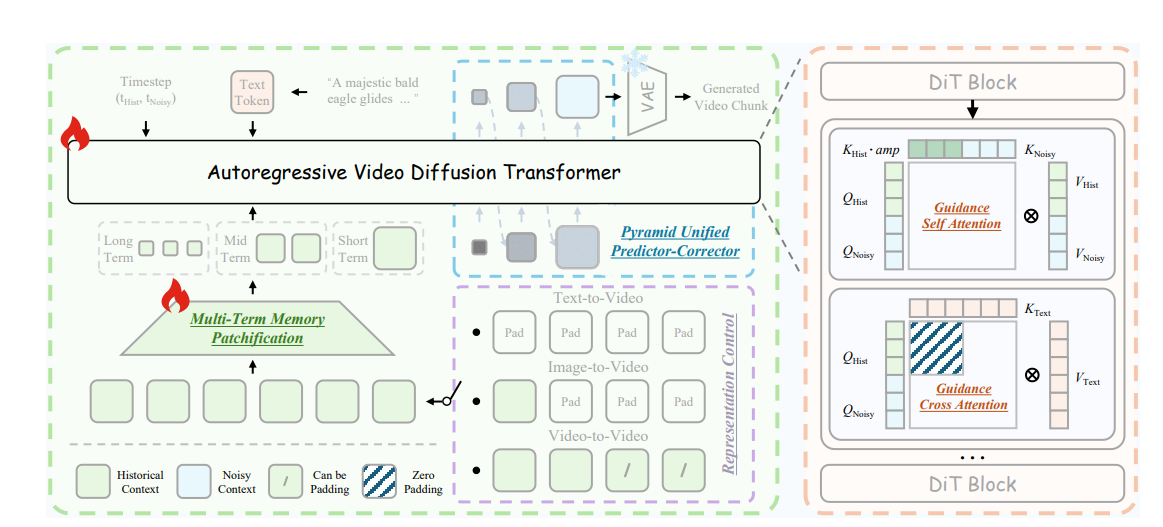
三大加速优化,砍断算力开销
为让 14B 模型实现实时生成,团队从时间维度、分辨率策略、采样层面进行了三重核心优化,大幅压缩算力开销:
-
时间维度精简:将噪声 latent 的帧数从 21 帧降至 9 帧,带来平方级的算力节省,直接压缩前向传播成本;
-
多尺度分辨率推理:先在低分辨率下完成画面大结构生成,再逐步细化到高分辨率,仅后期进入高成本计算区间,让推理效率最大化;
-
DMD 蒸馏压缩采样:并非简单减少扩散步数,而是将整个扩散轨迹学习为快速映射,把推理步数从 50 步压缩到 4 步,时间开销直接降低一个数量级。
昇腾原生优化,释放国产化算力潜力
为让模型在昇腾 Atlas A3 上高效运行,团队还做了一系列工程化优化,深度融合国产化算力生态的原生特性:
-
推出特征缓存方案(Latents Cache),预计算并存储耗时最高的引导词特征,「以查代算」让多轮迭代训练时间缩短 30%,释放 20% 显存资源;
-
全程基于昇腾平台完成训练与推理,适配 MindSpeed-MM 套件的 TP/SP 并行、MindCluster 断点续训、SmartSwap 等原生特性,解决了底层通信算子精度误差、非并行切分层推理崩溃等问题。
OSP-RealTime 14B 的落地,让 14B 级视频大模型正式迈入实时区间,视频生成不再局限于「几秒短片段」,而是具备了成为「持续运行系统」的算力基础,为互动视频、生成式游戏、实时虚拟世界等过去只存在于想象的应用,打开了落地大门。
国产化算力生态崛起,定义视频生成「公共基础设施」
从 UniWorld-OSP2.0 的「双原生」突破,到 OSP-RealTime 14B 的实时化落地,再到 Helios 的性能再升级,背后始终离不开北京大学鲲鹏昇腾科教创新卓越中心的算力赋能与技术支持。昇腾 NPU 的 Day-0 级别支持、鲲鹏 + 昇腾的国产化算力组合,成为这套视频生成框架的核心支撑,也让国产智算生态在视频生成领域占据了核心话语权。
UniWorld-OSP2.0 的价值,不仅在于实现了技术突破,更在于为行业打造了一套可复用、低成本、自主可控的公共基础设施:
-
为开发者蹚平了多尺度自回归细节模糊、token 早融合质量瓶颈、LLM 叠加 Flow 工程局限等技术深坑,节约了大量试错成本;
-
为国产智算生态提供了高价值的工程落地手册,解决了昇腾算力适配的各类底层问题,让开发者无需从零训练高耗能的 VAE 或调试脆弱的 DiT 架构,直接获得成熟工具链;
-
以开源模式凝聚行业力量,字节、腾讯等企业的二次开发,让这套框架逐渐成为产业级标准,推动视频生成从「实验室技术」走向「规模化商用」。
而从技术趋势来看,AI 视频生成的比拼早已脱离了「像素堆料」的初级阶段,正朝着语义理解深度、多模态协同效率、物理规律学习能力的高阶方向收敛,而 UniWorld-OSP2.0 展现出的跨模态对齐、物理一致性、实时生成能力,也让其朝着真正的通用视觉世界模型稳步迈进。
结语:视频生成的工业时代,由国产开源底座开启
Helios 的爆火,是 UniWorld-OSP2.0 核心技术的一次集中爆发,更是国产开源视频生成框架与国产化算力生态的一次完美协同。从 14B 参数量单卡实时生成,到「双原生」统一范式的收敛,再到产业级基础设施的成型,中国团队正在 AI 视频生成领域占据越来越重要的话语权。
随着 Open-Sora Plan 团队进一步开源 12 类风格化数据集及完整模型权重,这套开源框架将凝聚更多行业力量,推动视频生成真正迈入工业级应用阶段。而以鲲鹏、昇腾为核心的国产化算力生态,也将成为视频生成、具身智能、通用世界模型等下一代 AI 技术的核心支撑,让中国 AI 在核心技术与底层算力上实现双重自主可控。