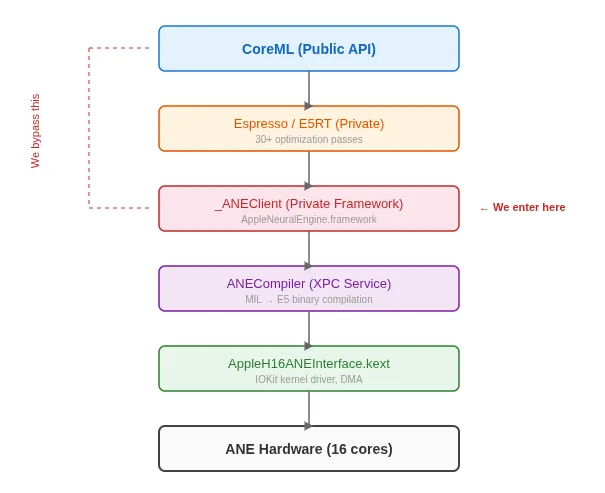
长期以来,苹果 M 系列芯片的 Neural Engine(ANE)都是 AI 硬件领域的 “黑盒”—— 开发者只能通过 CoreML 框架间接调用,其底层架构、指令集等核心信息从未公开。近日,开发者 maderix 通过挖掘 CoreML 底层逻辑,成功破解 ANE 的运行机制,揭露了一个惊人真相:苹果宣传的 M4 芯片 ANE “38 TOPS INT8 算力” 竟是营销包装的数字游戏,真实物理峰值算力仅 19 TFLOPS(FP16),同时曝光了 ANE 的核心硬件特性与优化痛点。
核心揭秘:38 TOPS 算力的 “水分” 所在
AI 领域中,INT8(8 位整数)量化的核心价值是 “牺牲少量精度,换取 2 倍吞吐提升”—— 相比 FP16(16 位浮点数),INT8 数据量减半,理论上处理速度应翻倍。但 maderix 的实测结果显示,ANE 运行 INT8 与 FP16 运算时,吞吐量几乎没有差异,由此揭开了苹果的算力包装套路:
ANE 在处理 INT8 运算时,并不会直接运算,而是先将 INT8 反量化(Dequantize)为 FP16,再进行计算。这意味着,INT8 运算本质上仍在消耗 FP16 的算力资源,所谓 “38 TOPS INT8”,只是将 FP16 的 19 TFLOPS 峰值算力乘以 2 得出的 “纸面数据”,并非真实的 INT8 硬件算力。
| 运算配置 | FP16 TFLOPS | INT8 TFLOPS | 性能比值 |
|---|---|---|---|
| 1024 单卷积 | 6.27 | 6.27 | 1.00x |
| 2048 单卷积 | 7.16 | 8.54 | 1.19x |
| 8 链卷积(1024) | 12.54 | 13.31 | 1.06x |
| 32 层深度卷积 | 18.50 | 18.83 | 1.02x |
| 64 层深度卷积 | 19.00 | - | - |
简单来说,这就像苹果宣传 “能快速扫描缩略图(INT8)”,实际却是先把缩略图还原成高清图(FP16)再扫描,所谓的 “速度优势” 根本不存在。
ANE 硬件真相:卷积优化器 + 深流水线架构
除了算力争议,maderix 的挖掘还揭露了 ANE 的核心硬件特性,打破了 “通用 AI 加速器” 的认知:
1. 本质是卷积引擎,矩阵乘法效率低下
ANE 的底层硬件设计专为卷积运算优化,而非标准矩阵乘法(MatMul):
-
卷积运算(如 1x1 Conv)走专用 “卷积数据通路”,吞吐量可飙升 3 倍;
-
矩阵乘法则走 “备用通道”(fallback 路径),需拆解、适配通用电路,效率极低。
这一特性在苹果开源的
ml-ane-transformers代码中已有暗示 —— 其中大量用卷积模拟 Transformer 结构,正是为了适配 ANE 的硬件优化方向。
2. 32MB SRAM 缓存,小批量更高效
通过扩展矩阵乘法规模的测试,maderix 反向推测出 ANE 内部搭载约 32MB 高速 SRAM 缓存:
-
当工作集(3 个 FP16 矩阵)小于 24MB 时,性能稳定;
-
超过 32MB(如 4096x4096 矩阵,工作集 96MB),性能暴跌至 4.0 TFLOPS,降幅超 30%。
这意味着 ANE 采用 “dataflow + on-chip memory” 设计(类似 TPU 架构),小批量运算能避免数据溢出 SRAM,效率更高。
3. 16 核流水线设计,需填满计算图才能跑满性能
ANE 的 16 个核心并非独立工作,而是深度流水线架构:
-
仅提交单个算子 / 操作时,大部分核心空转,硬件利用率仅 30%;
-
需将 16-64 个操作整合为一张计算图一次性提交,不同核心同步处理不同阶段任务,利用率才能拉满至 94%。
这说明 ANE 的性能并非 “单核算力 ×16”,而是依赖计算图的深度优化,更像 “自动化流水线” 而非 “多工人作坊”。
4. 0mW 空闲功耗,移动端能效顶尖
ANE 的电源管理能力堪称亮点:采用硬件级电源门控技术,空闲时完全断电,功耗为 0mW,避免泄漏损耗;峰值负载(18.4 TFLOPS)时功耗仅 2.79W,能效比达 6.6 TFLOPS/W,远超 M4 GPU(约 1.0 TFLOPS/W)、英伟达 A100(0.08 TFLOPS/W)等硬件。
实际使用痛点:CoreML 开销大,延迟敏感场景不友好
maderix 的测试还发现,ANE 的实际使用存在明显局限:
-
CoreML 框架开销高:小规模操作(如 1024 矩阵乘法)中,CoreML 的调度、编译开销是直接调用 ANE 的 3.1 倍,仅在 32 层以上深度卷积等高性能场景,开销占比才降至 3%;
-
延迟敏感场景适配差:LLM 令牌解码、实时推理等需要低延迟的场景,CoreML 的调度延迟会严重影响体验;
-
编译器内存泄漏:连续编译 119 次后会导致系统崩溃,需通过
exec()命令重启进程才能规避。
最优使用策略:ANE+SME 混合模式
结合 M4 芯片的 SME(可扩展矩阵扩展)技术,maderix 给出了 LLM 推理的最优方案 —— 混合模式:
-
ANE 负责预填充:处理大批量输入(如长文本、多轮对话上下文),利用高吞吐量和低功耗优势,快速建立 KV Cache;
-
SME 负责解码:处理单标记生成,依托 “零调度开销” 和灵活精度支持(INT8/FP32/FP64),降低推理延迟,保证对话流畅性。
这种分工完美适配 ANE 的 “高吞吐、低能效” 与 SME 的 “低延迟、高灵活”,是目前 M4 芯片运行 LLM 的最优解。
延伸发现:M3 Ultra ANE 算力接近 3090
值得一提的是,测试还发现 M3 Ultra 的 ANE 具备双集群设计(32 核),双线程启动后可实现 38.73 TFLOPS(FP16)的理论峰值,实际运行中最高达 36.58 TFLOPS,算力接近英伟达 3090 显卡,且功耗仅为后者的几十分之一,展现出极强的能效优势。
结语:ANE 是 “专用利器” 而非 “通用神器”
苹果 ANE 的底层挖掘,打破了 “高算力通用 AI 加速器” 的营销神话 —— 它本质是一款为卷积运算优化、依赖深度流水线的专用加速器,适合大批量、低延迟敏感的 AI 推理场景(如图像识别、语音处理),但在矩阵乘法密集的 LLM 推理、实时交互等场景中,存在明显局限。
对于开发者而言,想要充分发挥 ANE 性能,需针对性优化:采用卷积优先的模型结构、整合计算图以填满流水线、控制批量规模避免 SRAM 溢出。而对于普通用户,也需理性看待厂商的算力宣传 —— 数字背后的硬件逻辑与实际体验,才是核心价值所在。
你是否在使用苹果设备运行 AI 应用?有没有感受到不同场景下的性能差异?欢迎在评论区分享你的体验!