2026 年 3 月,中国 AI 巨头 DeepSeek 即将掀起行业风暴 —— 新一代旗舰模型 DeepSeek V4 确认于下周正式发布。这款蛰伏一年打磨的原生多模态大模型,以 “百万 token 上下文、跳过英伟达优先适配国产芯片、API 成本便宜 50 倍” 三大核心杀手锏,向 OpenAI、Google 等美国巨头发起正面挑战。随着发布日期临近,华尔街已陷入焦灼,市场担忧重演 2025 年 R1 发布时英伟达单日蒸发 5890 亿美元市值的 “黑色星期一”。

核心亮点:三大突破改写 AI 行业规则
DeepSeek V4 的发布绝非简单的模型迭代,而是中国 AI 从 “跟随” 到 “定义规则” 的战略转向,核心突破集中在三大维度:
1. 原生多模态:补齐短板,编码性能超越 GPT/Claude
过去 DeepSeek 以 “文字强手” 著称,代码生成与推理能力顶尖,但多模态一直是短板。V4 彻底补齐这一缺口,实现全方位能力升级:
-
全模态支持:原生理解并生成文本、图片、视频,泄露的 V4 Lite 版本(代号 “Sealion-lite”)在 SVG 图像生成上,未开启思考模式就超越了 V3.2 的思考模型水平;
-
超长上下文窗口:上下文容量飙升至 100 万 + token,较上一代提升近 8 倍,记忆准确率达 98.2%,可一次性处理整本专业书籍、整套合同或海量研究报告;
-
编码性能登顶:据接近发布的内部人士透露,V4 的代码生成与优化能力已超越当前 GPT 和 Claude 系列模型,成为开发者的新选择。

2. 国产芯片深度适配:跳过英伟达,实现自主可控
这是 V4 最具战略意义的突破,彻底打破 AI 行业 “顶级模型必适配英伟达” 的惯例:
-
反向操作破局:DeepSeek 绕开英伟达,未向其提供早期接入权限,转而与华为、寒武纪等国产芯片厂商深度合作,全面优化昇腾、寒武纪、海光等芯片的推理性能;
-
推理端自主落地:虽然训练阶段仍依赖英伟达高端 GPU,但推理环节已实现国产芯片全覆盖 —— 而推理是大模型商业化落地的核心环节,这一突破意味着中国 AI 可摆脱对海外芯片的依赖,实现 “用自己的芯片跑自己的模型”;
-
生态协同效应:国产芯片与本土大模型的深度绑定,将大幅降低 AI 落地成本,推动金融、法律、科研等垂直领域的规模化应用。
3. 50 倍成本优势:API 价格碾压对手,引发行业利润压缩
价格优势将成为 V4 颠覆市场的关键武器。据网友爆料,V4 的 API 输入成本仅为 0.27 美元 / 百万 token,而 OpenAI、Google 等竞争对手的价格高达 15 美元 / 百万 token,便宜幅度超 50 倍。
这一价格优势并非牺牲性能换来 —— 参考上一代 R1 模型以 GPT-4 十分之一的训练成本(约 560 万美元)实现同等水平性能,DeepSeek 的工程效率优势已得到验证。业内预测,V4 的低价策略将迫使全球 AI 厂商压缩利润空间,加速行业 “效率竞赛”。
市场震动:美股再迎 “DeepSeek 时刻”?
2025 年 1 月,DeepSeek R1 模型发布后,英伟达股价单日暴跌 17%,创下美国股市单家公司历史最大单日跌幅,纳斯达克综合指数下跌超 3%,博通、微软等科技巨头同步受挫。如今 V4 的综合实力更胜一筹,市场担忧将引发更剧烈的波动:
-
算力需求重构:若 V4 在国产芯片上跑出顶级性能,将直接冲击英伟达高端 GPU 的市场需求,华尔街对 AI 基础设施天量投资的合理性将再次受到质疑;
-
巨头估值承压:OpenAI、Anthropic 等依赖高定价 API 的企业,将面临 V4 的低价冲击,估值逻辑可能被重构;
-
投资情绪紧张:CNBC 报道称,多家投资机构已进入 “严阵以待” 状态,部分机构甚至建议抛售美股 AI 相关股票,规避潜在风险。
蛰伏一年:DeepSeek 的 “磨刀之路”
V4 的爆发并非偶然,而是 DeepSeek 持续迭代打磨的结果。自 2025 年 1 月 R1 发布后,团队进入 “静默模式”,专注技术积累:
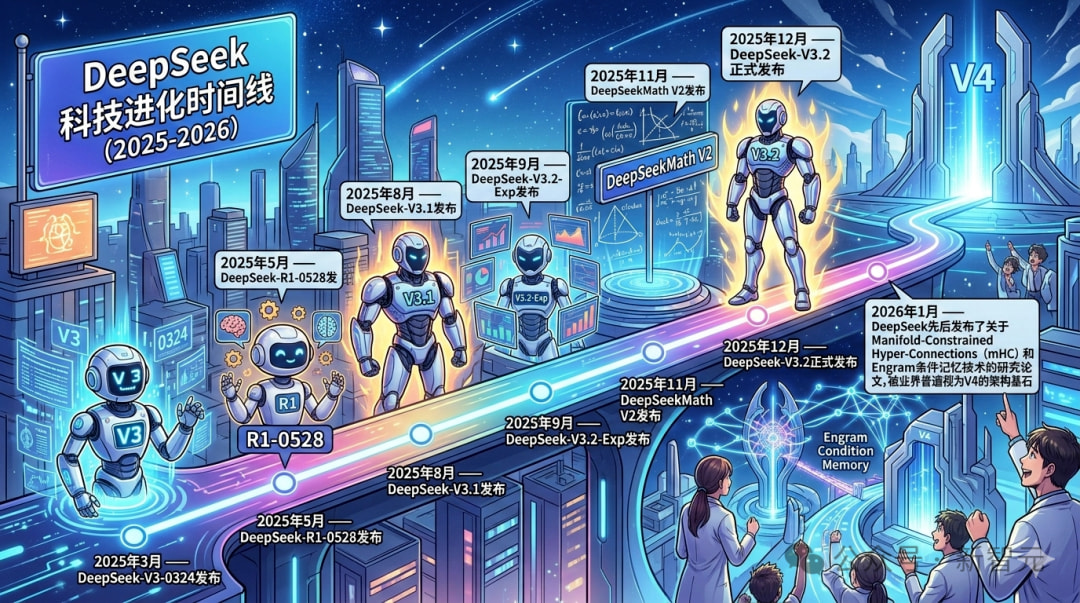
-
2025 年 3 月:V3.0 升级,吸收 R1 的强化学习技术,数学与编程能力超越 GPT-4.5;
-
2025 年 8 月:V3.1 发布,融合 V3 与 R1 能力,支持 “思考 / 非思考模式” 切换,SWE-bench 基准提升超 40%;
-
2025 年 9 月:引入 DeepSeek Sparse Attention 稀疏注意力机制,为超长上下文奠定基础;
-
2025 年 12 月:V3.2 在 IMO、IOI 竞赛中取得金牌级表现,将思考能力整合进工具调用;
-
2026 年 1 月:发布 mHC(流形约束超连接)与 Engram(条件记忆)技术,成为 V4 的架构基石。
舆论战升温:Anthropic 的 “蒸馏攻击” 指控遭反噬
就在 V4 发布前夕,美国 AI 公司 Anthropic 发起舆论反击,指控 DeepSeek、Moonshot AI 等三家中国企业 “创建 2.4 万个虚假账户,与 Claude 进行 1600 万次交互,实施工业级蒸馏攻击”。
但戏剧性的是,网友很快发现 Claude 存在致命 bug:用中文询问 “你是什么模型” 时,其回复竟是 “我是 DeepSeek V3”,通过官方 API 测试结果一致;用法语提问则自称 “ChatGPT”。这一乌龙让 Anthropic 的指控沦为笑柄,Reddit 网友直指这是 “有组织的 FUD 营销”,目的是在 V4 发布前抢占叙事高地,稀释其市场关注度。
行业影响:中国 AI 从 “蛮力” 到 “结构创新” 的进化
DeepSeek V4 的发布,标志着中国 AI 发展路径的根本性转变 —— 从依赖硬件蛮力,转向依靠架构创新与工程效率。美国的芯片出口管制,反而倒逼中国企业探索更高效的训练策略、更精妙的架构设计和更极致的资源优化,而这些创新的价值远超单一芯片。
下周,DeepSeek V4 将正式揭开面纱,同步发布简短技术说明,一个月后将推出完整技术报告,延续其开源共享的传统。这款模型不仅将改写全球 AI 的竞争格局,更将推动国产 AI 生态的全面成熟,让 “自主可控、高效低成本” 成为新的行业关键词。
全世界都在紧盯这场发布 —— 它不仅是一次模型升级,更是中国 AI 向全球展示 “另一条发展路径” 的重要时刻。