2026 年 2 月 27 日,昆仑天工正式发布多模态视频基础模型 SkyReels-V4,以 “1080p+32FPS 电影级输出、音视频原生同步、全模态输入 + 统一编辑” 三大核心突破,强势跻身 Artificial Analysis 文本生成视频(含音频)现役模型全球第 2 名,超越 Veo 3.1、Sora 2 等主流模型,标志着国产 AI 视频技术从 “单一功能合成” 迈入 “全流程一体化创作” 的新阶段。
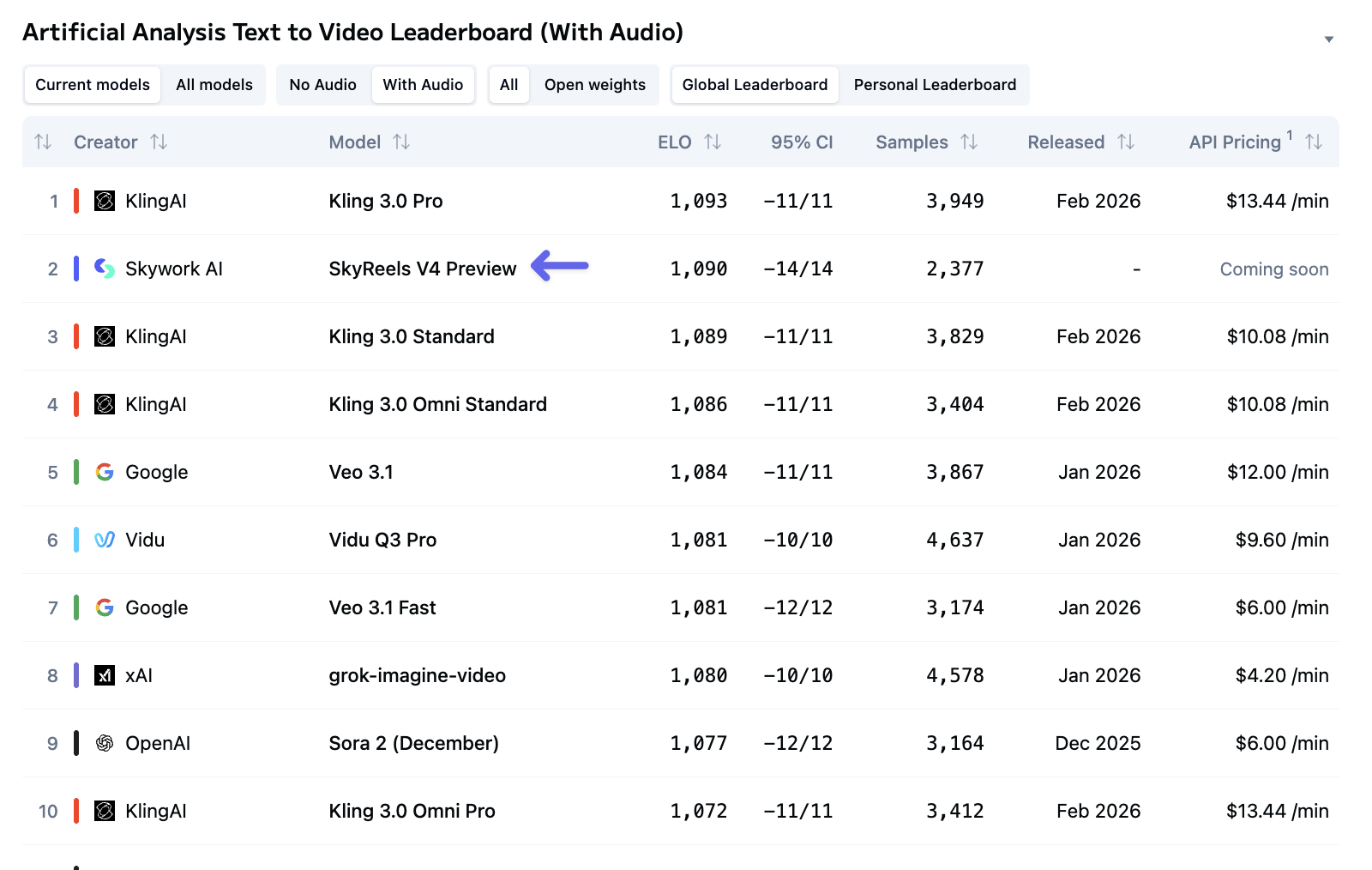
核心战绩:全球榜单 TOP2,实力碾压主流模型
根据独立机构 Artificial Analysis 的标准化测试,SkyReels-V4 的综合性能位居全球前列,核心排名与竞品对比极具竞争力:
| 排名 | 模型名称 | 开发者 | ELO 得分 | 发布时间 | API 定价(美元 / 分钟) |
|---|---|---|---|---|---|
| 1 | Kling 3.0 Pro | KlingAl | 1093 | 2026 年 2 月 | 13.44 |
| 2 | SkyReels V4 Preview | Skywork AI(昆仑天工) | 1090 | 2026 年 2 月 | 即将公布 |
| 3 | Kling 3.0 Standard | KlingAl | 1089 | 2026 年 2 月 | 10.08 |
| 5 | Veo 3.1 | 1084 | 2026 年 1 月 | 12.00 | |
| 9 | Sora 2 | OpenAI | 1077 | 2025 年 12 月 | 6.00 |
SkyReels-V4 不仅在现役模型中排名第二,在全球所有文本生成视频模型总榜中也位列第 4,其音视频同步生成能力更是打破行业痛点,实现了从 “画面生成” 到 “视听协同” 的关键跨越。
三大技术革命:重新定义 AI 视频创作
SkyReels-V4 的核心突破源于底层架构革新,彻底解决了传统视频模型 “音画不同步、功能分散、操作复杂” 的行业通病:
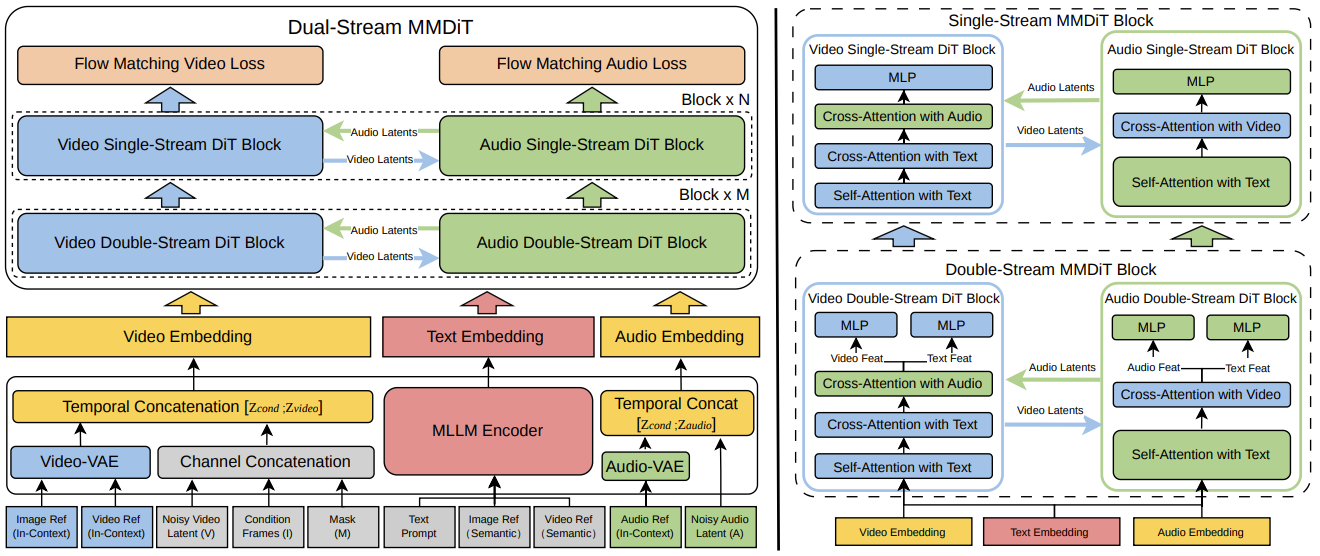
1. 双流 MMDiT 架构:音视频天生同步,告别 “缝合感”
传统模型的音频多为后期叠加,易出现口型对不上、音效延迟等问题。SkyReels-V4 采用对称双流架构,让视频与音频如同 “双胞胎” 协同生成:
-
双分支共享大脑:视频与音频分支拥有独立参数通道,但共享 MMLM 文本处理核心,确保语义理解一致;
-
双向跨注意力交互:生成过程中,音频流实时关注视频特征,视频流反向响应音频节奏,实现特征层面深度咬合;
-
时间尺度对齐:通过 RoPE 旋转位置编码频率缩放技术,将音频 44.1kHz 的高频特征与视频帧节奏匹配,彻底解决音画时间错位。
实测效果:“关公战秦琼” 场景中,人物台词发音与嘴唇翕动精准同步,兵器相撞的音效与火星四溅的视觉反馈严丝合缝,史诗感与真实感拉满。
2. 通道拼接统一框架:所有编辑都是 “填空题”
过去生成、修复、编辑需在多个工具间切换,SkyReels-V4 通过 “掩码 + 通道拼接” 技术,将所有任务统一为 “修复问题”,操作极简:
-
灵活掩码配置:全 0 掩码 = 从头生成(T2V),首帧 1 其余 0 = 图像续视频(I2V),指定区域 0 = 局部编辑,支持视频扩展、帧插值等全场景;
-
可视化编辑能力:可直接替换视频主体(如让北极狼跳迈克尔・杰克逊经典动作)、移除指定角色或字幕水印,修改后音频可同步重构,确保视听逻辑一致;
-
零学习成本:无需专业剪辑技能,自然语言指令即可完成复杂编辑,如 “移除视频右侧持手电筒的金发男子”。
3. VSA 稀疏注意力:1080p 输出成本降低 3 倍
生成高清长视频对算力要求极高,SkyReels-V4 通过 “草稿 + 精修” 策略 + 视频稀疏注意力(VSA)技术,实现效率与画质双赢:
-
分阶段生成:先快速生成低分辨率全序列,再对关键帧做超分辨率与帧插值优化;
-
VSA 提效:两阶段分层处理,先聚合时空块锁定关键区域,再对 Top-K 区域做密集注意力计算,算力成本降低 3 倍;
-
规格拉满:支持 512px(低延迟场景)到 1080p 分辨率,32FPS 帧率,最长 15 秒输出,新增 4:1、1:8 等极端宽高比,适配广告、短视频等多元场景。
全模态创作:文本 / 图像 / 视频一键生成,覆盖全场景
SkyReels-V4 是全球首个同时支持多模态输入、联合音视频生成、统一编辑的视频基础模型,真正实现 “一站式创作”:
1. 文本生成视频(T2V):电影级叙事不在话下
输入复杂镜头调度指令,模型可精准理解并执行多机位切换,保持主体与场景一致性。例如滑雪场景提示词:“中远景腾跃→低角度跟拍→特写雪粒飞溅→夕阳远景”,模型完美呈现电影级质感,物理运动学特征(如控板姿态、雪雾轨迹)真实可信。
2. 图像生成视频(I2V):静态图秒变动态大片
上传两张人物图像 + 文本指令,即可生成连贯剧情视频:
-
短剧场景:奢华室内 + 人物对话,中文口型咬字准确,微表情(眉头微蹙、眼神错愕)与台词情绪高度同步,背景配乐适时切入,营造沉浸式戏剧张力;
-
史诗场景:雷鸣荒野中人物对峙,吼声回荡、刀锏相撞火星四溅,慢动作与体积光效果拉满,数字角色具备真实生命力。
3. 跨模态编辑:万物皆可改,创意无边界
支持文本、图像、视频片段、音频参考等多模态输入,实现灵活创作:
-
角色替换:将视频舞者替换为北极狼,动作保持连贯;
-
风格迁移:把《爱乐之城》舞蹈视频中的角色替换为柴可夫斯基与《魔兽世界》吉安娜,风格统一且动作自然;
-
全局优化:基于参考音频生成匹配视频,或根据视频内容重构音效,确保视听协同。
生态与未来:开启内容创作 “全栈时代”
SkyReels-V4 的发布填补了昆仑天工 AI 生态在视听内容生产的关键拼图,与 Skywork 文本大模型、Mureka 音乐模型、Matrix Game 游戏模型形成协同矩阵,赋能广告、影视、短剧、社交等多元产业。
未来规划
-
功能升级:将支持 60 秒以上长视频生成、实时交互编辑;
-
生态开放:开放 API 与全系产品协同,支持二次开发;
-
场景深化:针对短剧、广告等垂直领域优化模板,降低创作门槛。
正如影视飓风 Tim 对全模态生成模型的评价:“这不是小革新,是推走行业过去流程的海啸”。SkyReels-V4 的出现,让 AI 视频创作从 “专业工具” 变为 “全民利器”,创作者无需纠结技术细节,只需聚焦创意与叙事,内容生产的工业化 “全栈时代” 已然到来。